
Abstract
-
Reccurence와 Convolution을 제거한 Attention 메커니즘 기반의 Transformer 네트워크 구조를 제안.
-
높은 병렬성으로 학습 시간을 단축함과 동시에 2 개의 기계 번역 테스크에서 우수한 성과를 보임.
-
WMT 2014 English-to-German 번역에서 28.4 BLEU score를, WMT 2014 English-to-French 번역에서 41.8 BLEU score를 달성.
Introduction
-
Recurrent model은 step \(t\)에서의 hidden state \(h_t\)를 계산하기 위해 이전 step (\(t-1\))의 hidden state인 \(h_{t-1}\)와 step \(t\)에서의 입력을 필요로 한다. 이러한 방식은 병렬성을 저해하여 학습에서의 계산 효율성을 떨어뜨린다.
-
이 연구에서 제안하는 Transformer 구조는 model 전체를 attention 메커니즘으로 구성하여 recurrence를 제거하고, 입력과 출력 사이에 global dependency를 이끌어낸다.
-
Tranformer 구조의 더 높은 병렬성으로 8개의 P100 GPU에서 12시간을 학습하는 것만으로 번역에서 SOTA 성능을 갱신한다.
Model Architecture
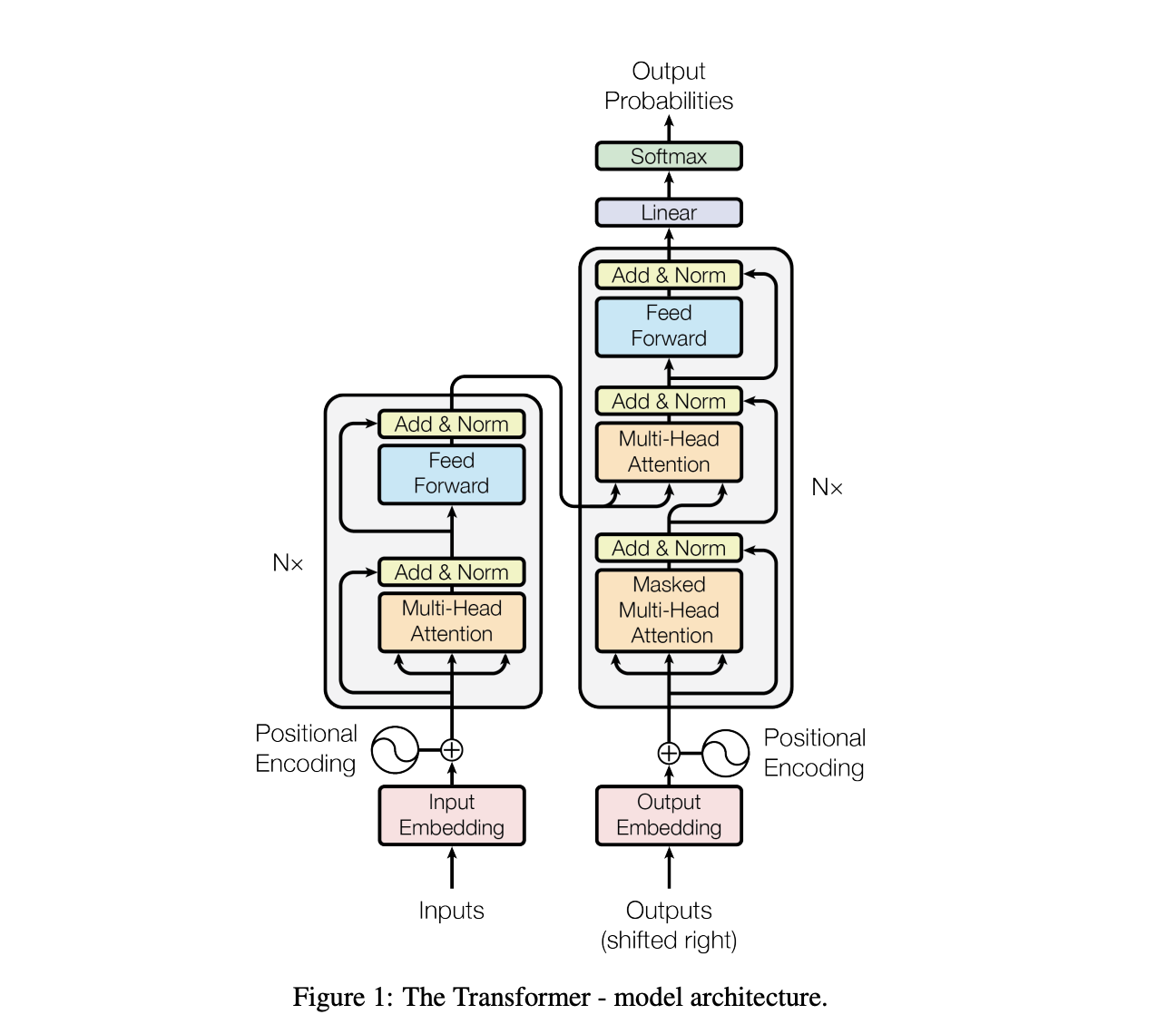
Encoder
-
6개의 동일한 layer로 구성되어 있으며, 각 layer는 2개의 sub-layer로 구성되어 있음.
-
첫 번째 sub-layer: Multi-head attention.
-
두 번째 sub-layer: Position-wise fully connected feed-forward network + layer normalization.
-
-
각 sub-layer에는 residual connection을 적용함.
-
Embedding layer는 512 차원의 출력을 내보냄.
# [2] https://github.com/jadore801120/attention-is-all-you-need-pytorch/blob/master/transformer/Layers.py
import torch
import torch.nn as nn
class EncoderLayer(nn.Module):
'''Compose with two layers.'''
def __init__(
self,
d_model: int,
d_inner: int,
d_head: int,
d_k: int,
d_v: int,
dropout: float = 0.1
) -> None:
super().__init__()
self.attention = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
self.feed_forward = PointwiseFeedFoward(d_model, d_inner, dropout=dropout)
def forward(
self,
enc_input: torch.Tensor,
slf_attn_mask: torch.Tensor = None,
) -> torch.Tensor:
enc_output, enc_slf_attn = self.slf_attn(
enc_input, enc_input, enc_input, mask=slf_attn_mask,
)
enc_output = self.pos_ffn(enc_output)
return enc_output, enc_slf_attn
Decoder
-
6개의 동일한 layer로 구성되어 있으며, 각 layer는 3개의 sub-layer로 구성되어 있음.
-
첫 번째 sub-layer: Masked-multi-head attention.
-
두 번째 sub-layer: Multi-head attention.
-
세 번째 sub-layer: Point-wise fully connected feed-forward network + layer normalization.
-
-
Position \(i\)에서의 출력은 \(i-1\)까지의 출력만을 참고해야 하기 때문에 Decoder stack의 self-attention에는 masking이 적용된다.
# [2] https://github.com/jadore801120/attention-is-all-you-need-pytorch/blob/master/transformer/Layers.py
class DecoderLayer(nn.Module):
'''Compose with three layers.'''
def __init__(
self,
d_model: int,
d_inner: int,
n_head: int,
d_k: int,
d_v: int,
dropout: float=0.1
) -> None:
super().__init__()
self.slf_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
self.enc_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
self.pos_ffn = PositionwiseFeedForward(d_model, d_inner, dropout=dropout)
def forward(
self,
dec_input: torch.Tensor,
enc_output: torch.Tensor,
slf_attn_mask: torch.Tensor=None,
dec_enc_attn_mask: torch.Tensor=None,
) -> torch.Tensor:
dec_output, dec_slf_attn = self.slf_attn(
dec_input, dec_input, dec_input, mask=slf_attn_mask,
)
dec_output, dec_enc_attn = self.enc_attn(
dec_output, enc_output, enc_output, mask=dec_enc_attn_mask,
)
dec_output = self.pos_ffn(dec_output)
return dec_output, dec_slf_attn, dec_enc_attn
Attention
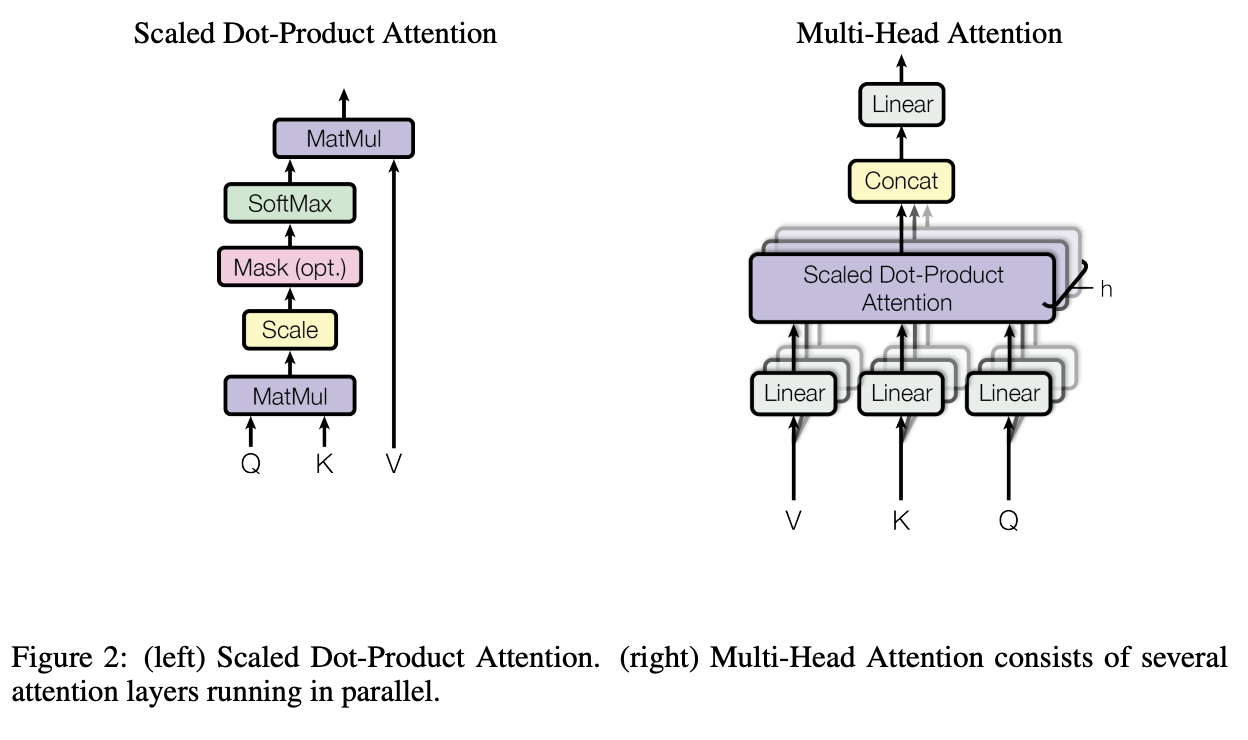
Scaled Dot-Product Attention
\[\text{Attention}(Q,K,V)=\text{softmax}(\frac{QK^T}{\sqrt{d_k}})V\\ d_k: \text{Dimension of queries and keys}.\]-
Query, Key, Value 세 개의 입력을 받는다.
-
Query는 문장을 구성하는 각 word와 매칭되는 벡터이고, Key와 Value는 문장을 구성하는 모든 words와 매칭되는 벡터다. 예를 들어 “jane visits africa”라는 문장이 주어졌을 때, 우리는 jane이라는 단어(query)를 보면서 문장 내에 jane과 가장 연관성이 높은 단어(visits)로 초점을 옮겨간다. Attention은 이 과정과 유사하다. jane과 가장 유사도가 높은 단어를 추론하기 위해 문장을 구성하는 모든 요소 jane / visits / africa에 대한 key와 query를 내적한 뒤 softmax를 통해 이를 확률분포로 변환한다 [4].
-
확률분포에 \(\sqrt{d_k}\)를 나누는 것에 대해 저자들은 내적으로 인해 값의 크기가 너무 커지는 것을 방지하기 위함이라 언급한다. 예를 들어 \(q\)와 \(k\)가 각각 mean 0, variance 1 분포의 랜덤한 값을 가진 벡터로 초기화되었다고 가정해보자. 이때 \(q\)와 \(k\)의 내적 결과는 mean 0, variance \(d_k\)가 될 것이다 (\(q\)와 \(k\)의 차원은 \(d_k\)). 내적 결과에 \(\sqrt{d_k}\)를 나눔으로써 variance를 1로 유지할 수 있다. 즉, 이 과정은 \(std=\sqrt{d_k}\)로 standardization하는 것과 동일하다.
-
최종적으로 확률분포와 value를 곱함으로써 query와 연관된 value를 좀 더 강조할 수 있게 된다.
# [2] https://github.com/jadore801120/attention-is-all-you-need-pytorch/blob/master/transformer/Modules.py
class ScaledDotProductAttention(nn.Module):
'''Scaled Dot-Product Attention.'''
def __init__(
self,
temperature: float,
attn_dropout: float=0.1,
) -> None:
super().__init__()
self.temperature = temperature
self.dropout = nn.Dropout(attn_dropout)
def forward(
self,
q: torch.Tensor,
k: torch.Tensor,
v: torch.Tensor,
mask: torch.Tensor=None,
) -> torch.Tensor:
attn = torch.matmul(q / self.temperature, k.transpose(2, 3))
if mask is not None:
attn = attn.masked_fill(mask == 0, -1e9)
attn = self.dropout(F.softmax(attn, dim=-1))
output = torch.matmul(attn, v)
return output, attn
Multi-Head Attention
저자들은 하나의 attention 함수를 사용하는 것보다 각자 다른 가중치를 가진 \(h\)개의 attention 연산을 하는 것이 좀 더 효과적이라 말한다. Multi-head attention을 사용함으로써 모델은 다수의 representation subspaces에서 서로 다른 위치에 대한 attention 정보를 취득할 수 있다.
\[\text{MultiHead}(Q,K,V) = Concat(head_1, ..., head_h)W^O\\ \text{where } head_i = \text{Attention}(QW^Q_i, KW^K_i, VW^V_i)\]- \[W_i^Q \in \mathbb{R}^{d_{model} x d_k}, W_i^K \in \mathbb{R}^{d_{model} x d_k}, W_i^V \in \mathbb{R}^{d_{model} x d_v}\]
- \[W_i^O \in \mathbb{R}^{hd_{v} x d_{model}}\]
- 논문에서는 \(h=8\)의 parallel attention layers를 사용했으며, \(d_k=d_v=d_{model}/h=64\)로 차원을 설정했다.
# [2] https://github.com/jadore801120/attention-is-all-you-need-pytorch/blob/master/transformer/SubLayers.py
class MultiHeadAttention(nn.Module):
'''Multi-Head Attention module.'''
def __init__(
self,
n_head: int,
d_model: int,
d_k: int,
d_v: int,
dropout: float=0.1,
) -> None:
super().__init__()
self.n_head = n_head
self.d_k = d_k
self.d_v = d_v
self.w_qs = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_ks = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_vs = nn.Linear(d_model, n_head * d_v, bias=False)
self.fc = nn.Linear(n_head * d_v, d_model, bias=False)
self.attention = ScaledDotProductAttention(temperature=d_k ** 0.5)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
def forward(
self,
q: torch.Tensor,
k: torch.Tensor,
v: torch.Tensor,
mask: Optional[torch.Tensor]=None,
) -> torch.Tensor:
d_k, d_v, n_head = self.d_k, self.d_v, self.n_head
sz_b, len_q, len_k, len_v = q.size(0), q.size(1), k.size(1), v.size(1)
residual = q
# Pass through the pre-attention projection: b x lq x (n*dv)
# Separate different heads: b x lq x n x dv
q = self.w_qs(q).view(sz_b, len_q, n_head, d_k)
k = self.w_ks(k).view(sz_b, len_k, n_head, d_k)
v = self.w_vs(v).view(sz_b, len_v, n_head, d_v)
# Transpose for attention dot product: b x n x lq x dv
q, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2)
if mask is not None:
mask = mask.unsqueeze(1) # For head axis broadcasting.
q, attn = self.attention(q, k, v, mask=mask)
# Transpose to move the head dimension back: b x lq x n x dv
# Combine the last two dimensions to concatenate all the heads together: b x lq x (n*dv)
q = q.transpose(1, 2).contiguous().view(sz_b, len_q, -1)
q = self.dropout(self.fc(q))
q += residual
q = self.layer_norm(q)
return q, attn
Position-wise Feed-Forward Networks
각 layer는 attention sub-layer와 함께 fully-connected feed-forward network를 포함한다. 이 계층은 ReLU activation이 두 개의 linear transformation 사이에 있는 형태이다.
\[FFN(x) = max(0, xW_1 + b_1)W_2 + b_2\]- 입력과 출력은 \(d_{model}=512\) 차원이고, 안쪽 linear transformation의 출력은 \(d_{ff}=2048\) 차원이다.
# [2] https://github.com/jadore801120/attention-is-all-you-need-pytorch/blob/master/transformer/SubLayers.py
class PositionwiseFeedForward(nn.Module):
'''A two-feed-forward-layer module.'''
def __init__(
self,
d_in: int,
d_hid: int,
dropout: float=0.1,
) -> None:
super().__init__()
self.w_1 = nn.Linear(d_in, d_hid) # position-wise
self.w_2 = nn.Linear(d_hid, d_in) # position-wise
self.layer_norm = nn.LayerNorm(d_in, eps=1e-6)
self.dropout = nn.Dropout(dropout)
def forward(
self,
x: torch.Tensor,
) -> torch.Tensor:
residual = x
x = self.w_2(F.relu(self.w_1(x)))
x = self.dropout(x)
x += residual
x = self.layer_norm(x)
return x
Embeddings and Softmax
Input tokens와 output tokens를 \(d_{model}\)차원의 벡터로 변환해주는 학습가능한 embedding을 사용한다. 또한 softmax 계산 직전에는 학습 가능한 linear transformation을 적용한다. 이 세가지에 각각 별도의 weight matrices로 정의한다면 어떻게 될까? 30k개의 토큰과 512 embedding size의 정보를 가진 matrix를 예로 들어보자. 이 matrix는 15.3 million의 파라미터를 가지게 된다. 문제는 이런 matrix가 세 개 모여서 총 46 million까지 파라미터가 늘어난다는 것이다 [6].
본 논문에서는 Press, O. and Wolf, L.[5]의 제안에 따라 Encoding, Decoding에서의 embedding layers와 softmax 직전의 linear transformation에 동일한 가중치를 사용한다 (a.k.a weight tying).
# [6] https://github.com/jsbaan/transformer-from-scratch/blob/main/transformer.py#L33
class Transformer(nn.Module):
def __init__(
self,
...
self.embed = nn.Embedding(vocab_size, hidden_dim, padding_idx=padding_idx)
self.encoder = TransformerEncoder(
self.embed, hidden_dim, ff_dim, num_heads, num_layers, dropout_p
)
self.decoder = TransformerDecoder(
self.embed,
hidden_dim,
...
# [6] https://github.com/jsbaan/transformer-from-scratch/blob/main/decoder.py#L44
class TransformerDecoder(nn.Module):
def __init__(
self,
embedding: torch.nn.Embedding,
hidden_dim: int,
...
self.output_layer = nn.Linear(hidden_dim, vocab_size, bias=False)
# Note: a linear layer multiplies the input with a transpose of the weight matrix, so no need to do that here.
if tie_output_to_embedding:
self.output_layer.weight = nn.Parameter(self.embed.weight)
...
또한 저자들은 embedding weight에 상수 \(\sqrt{d_{model}}\)를 곱한 것을 언급한다. 이에 대해서는 의견이 분분한데 그 중 대표적인 것들은 다음과 같다. [7]
-
embedding과 linear transformation이라는 서로 다른 연산에서 잘 동작하게 하기 위해.
-
그다지 필요하지 않음.
-
Positional encoding의 값을 상대적으로 작게 하기 위해. Embedding vector가 가지고 있는 고유한 의미를 잃지 않게 하기 위함.
Positional Encoding (Sinusoids)
이 모델에는 recurrence가 없기 때문에 sequence의 순서에 대한 정보를 넣어줄 필요가 있다. 논문에서는 embedding과 동일한 차원의 positional vector를 embedding에 합하는 방식을 제안한다. Positional vector는 word의 position \(pos\)와 vector의 dimension \(i\)에 대해 다음과 같은 sine, cosine 주기함수로 정의한다.
\[PE_{(pos,2i)}=sin(pos/10000^{2i/d_{model}})\\ PE_{(pos,2i+1)}=cos(pos/10000^{2i/d_{model}})\]Positional vector는 다음 두 가지 조건을 만족해야 한다. [8]
-
Positional vector는 시퀀스의 길이나 입력에 관계없이 동일한 식별자를 가져야 한다.
-
Positional vector는 적당히 작은 크기의 값을 가져야 한다. Positional vector는 word embedding에 합산되므로, 그 크기가 너무 크면 단어간의 상관관계나 의미를 유추할 수 있는 정보를 상대적으로 손실할 수 있다.
위와 같이 주기함수로 positional vector를 정의하면 값이 일정한 구간으로 내에서 반복되므로 값이 너무 커지거나 값의 편차가 너무 커지는 것을 방지할 수 있다. 또한 단어의 위치나 vector의 각 차원에 따라 서로 다른 주기함수를 사용하기 때문에 위치정보를 표시하기 위한 식별자로써의 역할을 할 수 있다.
# [6] https://github.com/jsbaan/transformer-from-scratch/blob/main/positional_encodings.py
class SinusoidEncoding(torch.nn.Module):
"""
Mostly copied from
https://uvadlc-notebooks.readthedocs.io/en/latest/tutorial_notebooks/tutorial6/Transformers_and_MHAttention.html
"""
def __init__(
self,
hidden_dim: int,
max_len: int=5000,
) -> None:
"""
Inputs
d_model - Hidden dimensionality of the input.
max_len - Maximum length of a sequence to expect.
"""
super().__init__()
# Create matrix of [SeqLen, HiddenDim] representing the positional encoding for max_len inputs
pos_embed = torch.zeros(max_len, hidden_dim)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(
torch.arange(0, hidden_dim, 2).float() * (-math.log(10000.0) / hidden_dim)
)
pos_embed[:, 0::2] = torch.sin(position * div_term) # 2i
pos_embed[:, 1::2] = torch.cos(position * div_term) # 2i + 1
pos_embed = pos_embed.unsqueeze(0)
# register_buffer => Tensor which is not a parameter, but should be part of the modules state.
# Used for tensors that need to be on the same device as the module.
# persistent=False tells PyTorch to not add the buffer to the state dict (e.g. when we save the model)
self.register_buffer("pos_embed", pos_embed, persistent=False)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Adds positional embeddings to token embeddings.
N = batch size
L = sequence length
E = embedding dim
:param x: token embeddings. Shape: (N, L, E)
:return: token_embeddings + positional embeddings. Shape: (N, L, E)
"""
x = x + self.pos_embed[:, : x.size(1)]
return x
Computational Complexity

-
아주 긴 문장을 다뤄야 할때 size \(r\) 만큼의 neighborhood만을 볼 수 있다는 제약이 생길 수 있는데, 이를 restricted self-attention라 표현했다.
-
Convolutional의 Maximum Path Length (입력 \(n\)에 대해 몇 번의 연산을 해야 하는지)는 contiguous kernel일 경우 \(O(n/k)\), dilated convolution의 경우 \(O(log_k(n))\)이라 언급한다.
Training
Training Data and Batching
-
4.5 million sentence pairs로 구성된 WMT 2014 English-German dataset으로 학습.
- Source-target vocabulary of about 37000 tokens.
-
36 million sentence pairs로 구성된 WMT 2014 English-French dataset으로 학습.
- 32000 word-piece vocabulary.
-
Sentences는 byte-pair encoding으로 인코딩.
-
각 training batch는 약 25000개의 source token과 약 25000개의 target token을 포함한 sentence pair set으로 구성.
Hardware and Schedule
-
8개의 NVIDIA P100 GPU 사용.
-
각 training step은 약 0.4초가 걸렸으며, 약 12시간동안 총 100,000 스텝을 수행.
-
Big model의 경우 step 당 1초가 걸렸으며, 3.5일간 300,000 스텝을 수행.
Optimizer
-
Adam Optimizer 사용 (\(beta_1=0.9\), \(beta_2=0.98\), \(\epsilon=10^{-9}\)).
-
Learning rate는 warmup step 동안 선형으로 증가하다가 이후 step number에 따라 inverse square root에 비례하여 떨어지게끔 정의. (warmup_steps = 4000)
Regularization
-
Residual Dropout 사용 (sublayer input과 합산하기 이전. dropout=0.1).
-
Embedding과 positional encoding을 합산한 것에도 dropout 적용.
Label Smoothing
- 학습에서 label smoothing 사용. (\(\epsilon_{ls}=0.1\))
Results
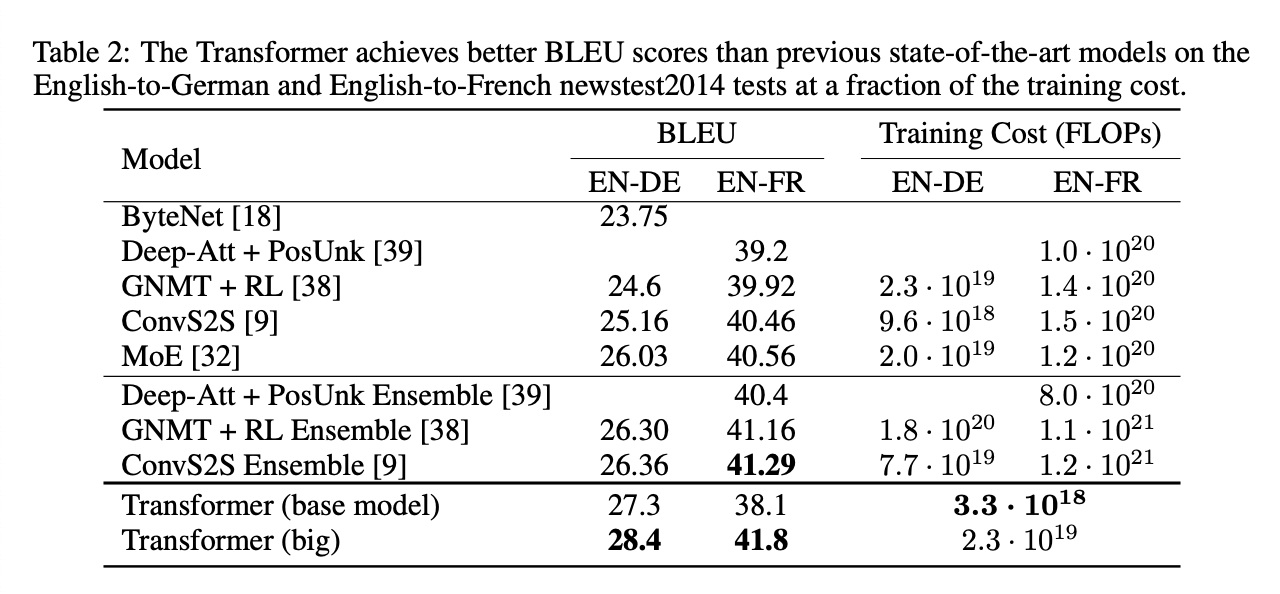
-
Base model의 경우 마지막 5개 checkpoints를 평균. (checkpoint 당 10분 간격)
-
Big model의 경우 마지막 20개 checkpoints를 평균.
-
Beam search 사용 - beam size: 4, length penalty \(\alpha=0.6\).
추론시의 최대 문장 길이는 input_length + 50으로 지정. (early termination 가능)
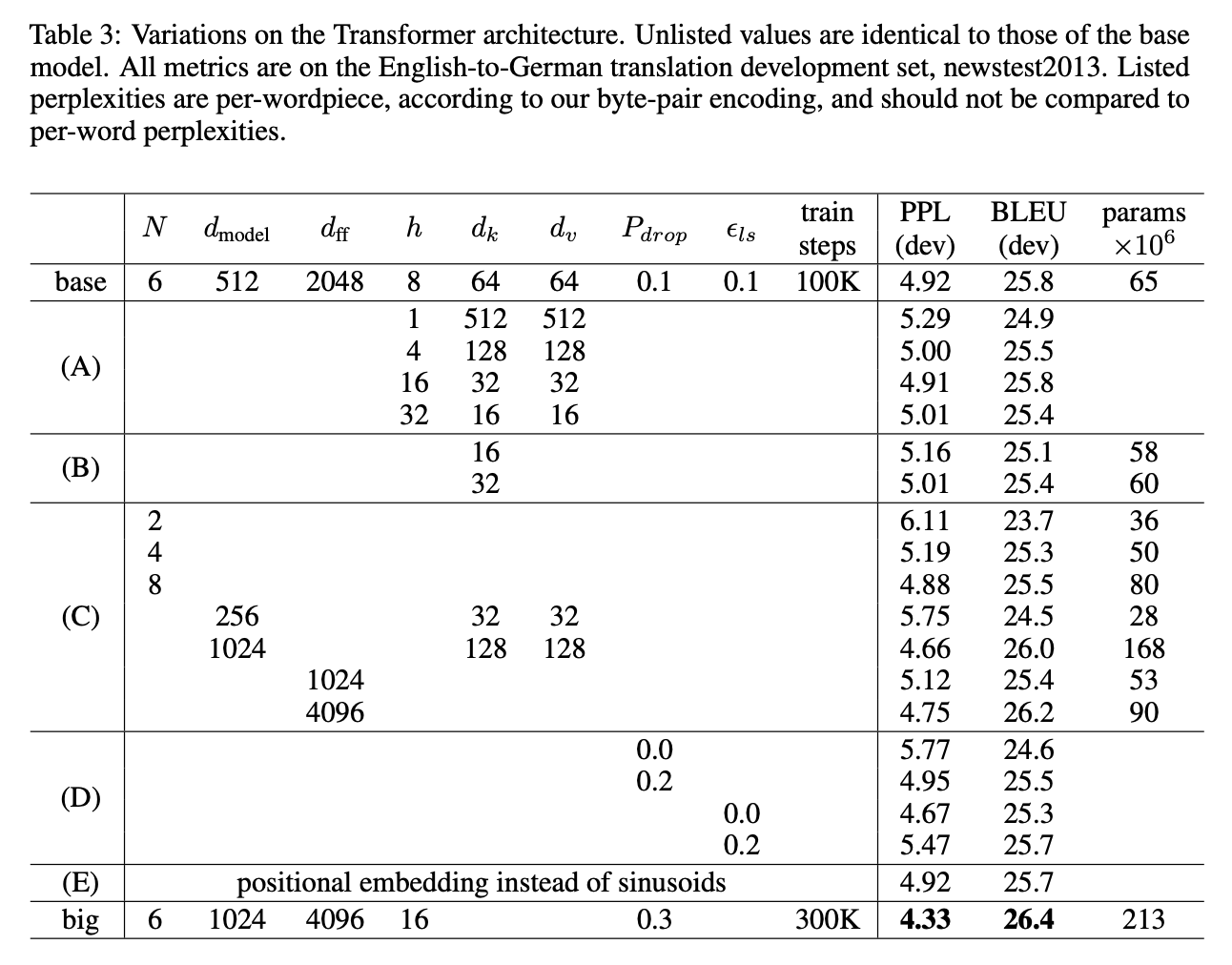
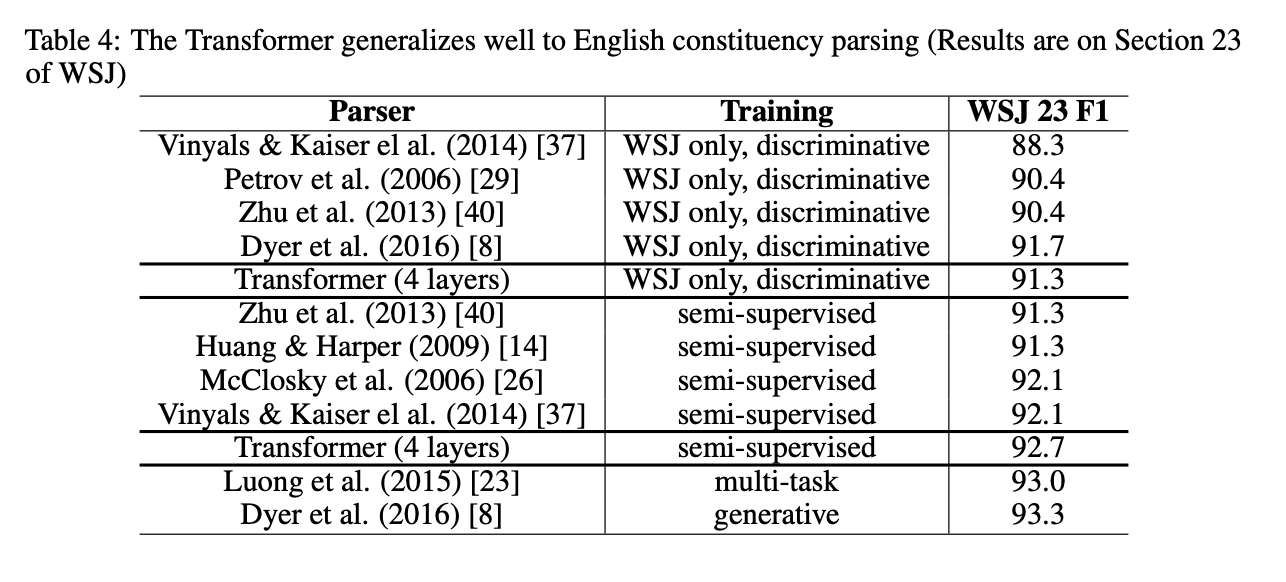
-
Best setting에 비해 single-head의 성능이 떨어짐. Head가 너무 많은 경우에도 성능이 떨어짐.
-
Sinusoids 대신 positional embedding을 사용했을때 baseline과 비교해 유의미한 성능차이가 없음. 저자들은 training data 보다 긴 길이의 문장을 추론 할때 learnable parameter 보다 Sinusoids가 좀 더 유리하리라 판단.
Conclusion
-
Attention으로만 이루어진 첫 번째 sequence transduction model을 발표.
-
Recurrent 또는 convolutional layer 기반의 네트워크에 비해 빠르게 학습 가능하면서도 WMT 2014 English-to-German and WMT 2014 English-to-French translation tasks에서 SOTA의 성능을 달성.
-
번역 뿐만 아니라 Image, audio, video 입출력의 다른 task에도 attention-based model을 적용해볼 예정.
Appendix
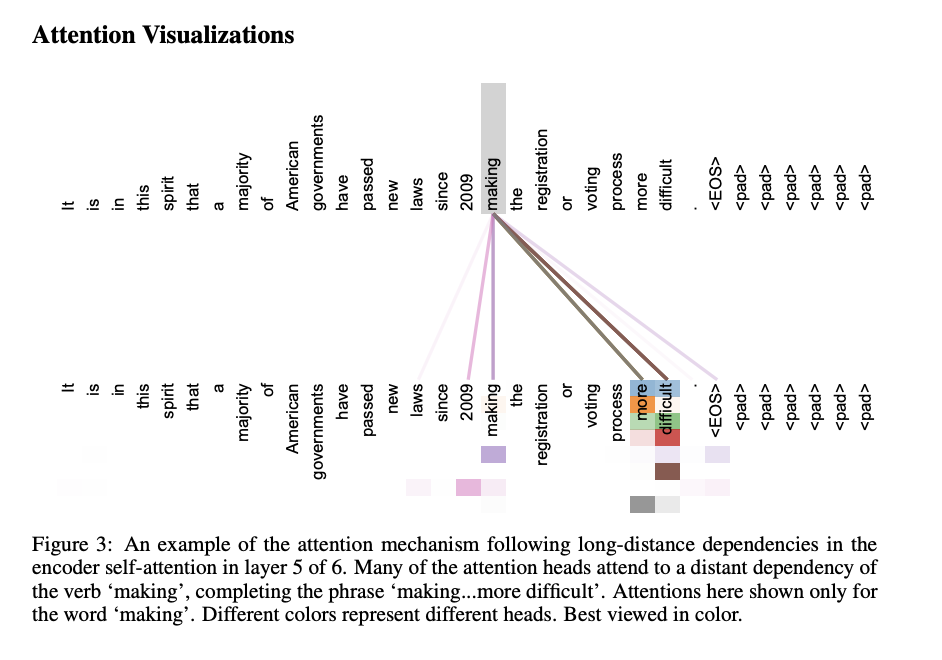
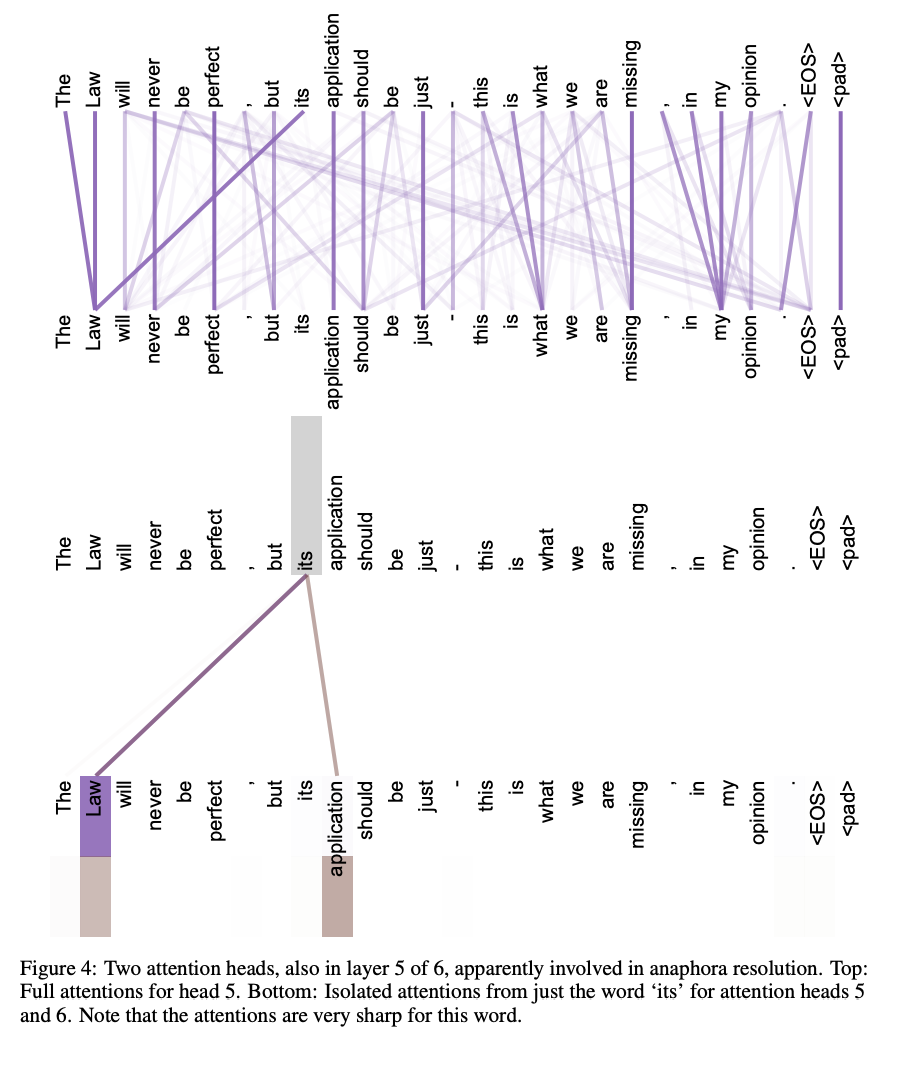
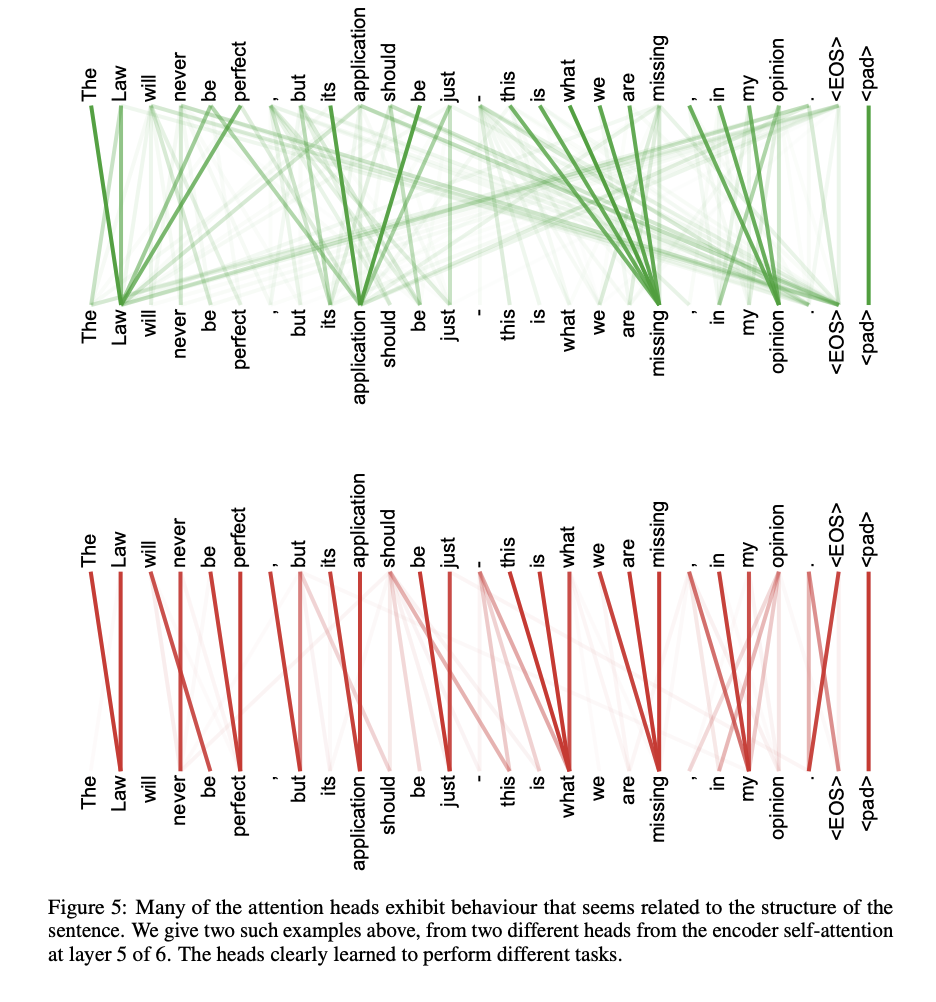
References
-
Vaswani, A. et al. (2017). Attention Is All You Need. arXiv preprint arXiv:1706.03762.
-
Huang, Y. (2020). Attention is all you need: A Pytorch Implementation. [Online] Available at: https://github.com/jadore801120/attention-is-all-you-need-pytorch [Accessed 01 Apr. 2023].
-
Huang, A. et al. (2022). The Annotated Transformer. [Online] Available at: http://nlp.seas.harvard.edu/annotated-transformer [Accessed 01 Apr. 2023].
-
Dontloo et al. (2019). What exactly are keys, queries, and values in attention mechanisms?. [Online] Available at: https://stats.stackexchange.com/questions/421935/what-exactly-are-keys-queries-and-values-in-attention-mechanisms [Accessed 02 Apr. 2023].
-
Press, O. and Wolf, L. (2016). Using the output embedding to improve language models. arXiv preprint arXiv:1608.05859.
-
Baan, J. (2022). Implementing a Transformer from Scratch. [Online] Available at: https://towardsdatascience.com/7-things-you-didnt-know-about-the-transformer-a70d93ced6b2 [Accessed 02 Apr. 2023].
-
Noe et al. (2021). Transformer model: Why are word embeddings scaled before adding positional encodings?. Available at: https://datascience.stackexchange.com/questions/87906/transformer-model-why-are-word-embeddings-scaled-before-adding-positional-encod [Accessed 02 Apr. 2023].
-
Lee, M. (2022). 트랜스포머(Transformer) 파헤치기-1.Positional Encoding. [Online] Available at: https://www.blossominkyung.com/deeplearning/transfomer-positional-encoding [Accessed 02 Apr. 2023].